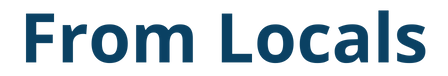

'...', "..."Ak v jazyku Python prefixujete tieto reťazcové literály jedným z nasledujúcich znakov, hodnota sa stane reťazcom bez rozbalenia escape sekvencie.
rR
Užitočné pri práci s reťazcami, ktoré používajú veľa spätných lomiek, ako sú cesty systému Windows a vzory regulárnych výrazov.
Tu sú uvedené tieto informácie.
- escape sekvencia
- Ignorovanie (zakázanie) escape sekvencií v surových reťazcoch
- Previesť normálny reťazec na nespracovaný reťazec:
repr() - Všimnite si spätné lomítko na konci.
escape sekvencia
V jazyku Python sa znaky, ktoré nie je možné reprezentovať v normálnom reťazci (napríklad tabulátory a nové riadky), opisujú pomocou escape sekvencií so spätnými lomkami, podobne ako v jazyku C. Príklad escape sekvencie je uvedený nižšie.
\t\n
s = 'a\tb\nA\tB'
print(s)
# a b
# A B
Ignorovanie (zakázanie) escape sekvencií v surových reťazcoch
'...', "..."Ak takýto reťazcový literál prefixujete jedným z nasledujúcich znakov, hodnota sa stane reťazcom bez rozbalenia escape sekvencie. Takýto reťazec sa nazýva surový reťazec.
rR
rs = r'a\tb\nA\tB'
print(rs)
# a\tb\nA\tB
Neexistuje žiadny špeciálny typ s názvom raw string type, je to len typ reťazca a rovná sa normálnemu reťazcu so spätným lomítkom, ktorý je reprezentovaný takto\\
print(type(rs))
# <class 'str'>
print(rs == 'a\\tb\\nA\\tB')
# True
V normálnom reťazci sa escape sekvencia považuje za jeden znak, ale v nespracovanom reťazci sa spätné lomítka tiež počítajú ako znaky. Dĺžka reťazca a jednotlivých znakov je nasledovná.
print(len(s))
# 7
print(list(s))
# ['a', '\t', 'b', '\n', 'A', '\t', 'B']
print(len(rs))
# 10
print(list(rs))
# ['a', '\\', 't', 'b', '\\', 'n', 'A', '\\', 't', 'B']
Cesta k systému Windows
Použitie surového reťazca je užitočné, keď chcete reprezentovať cestu systému Windows ako reťazec.
Cesty v systéme Windows sa oddeľujú spätnými lomkami, takže ak použijete normálny reťazec, musíte cestu takto escapovať, ale ak použijete nespracovaný reťazec, môžete ho zapísať tak, ako je. Hodnoty sú ekvivalentné.\\
path = 'C:\\Windows\\system32\\cmd.exe'
rpath = r'C:\Windows\system32\cmd.exe'
print(path == rpath)
# True
Všimnite si, že reťazec končiaci nepárnym počtom spätných lomiek bude mať za následok chybu, ako je opísané nižšie. V tomto prípade je potrebné zapísať reťazec ako normálny reťazec alebo ho spojiť tak, že zapíšete iba koniec reťazca ako normálny reťazec.
path2 = 'C:\\Windows\\system32\\'
# rpath2 = r'C:\Windows\system32\'
# SyntaxError: EOL while scanning string literal
rpath2 = r'C:\Windows\system32' + '\\'
print(path2 == rpath2)
# True
Prevod normálnych reťazcov na nespracované reťazce pomocou funkcie repr()
Ak chcete previesť normálny reťazec na surový reťazec, pričom ignorujete (vypnete) escape sekvencie, môžete použiť vstavanú funkciu repr().
s_r = repr(s)
print(s_r)
# 'a\tb\nA\tB'
Funkcia repr() vráti reťazec reprezentujúci objekt tak, aby mal rovnakú hodnotu, ako keď bol odovzdaný funkcii eval(), s úvodnými a koncovými znakmi.
print(list(s_r))
# ["'", 'a', '\\', 't', 'b', '\\', 'n', 'A', '\\', 't', 'B', "'"]
Pomocou rezov môžeme získať reťazec ekvivalentný nespracovanému reťazcu s pripojeným r.
s_r2 = repr(s)[1:-1]
print(s_r2)
# a\tb\nA\tB
print(s_r2 == rs)
# True
print(r'\t' == repr('\t')[1:-1])
# True
Všimnite si spätné lomítko na konci.
Keďže spätné lomítko uniká znaku úvodzoviek bezprostredne za ním, ak je na konci reťazca nepárny počet spätných lomítok, dôjde k chybe. Párny počet spätných lomiek je v poriadku.
# print(r'\')
# SyntaxError: EOL while scanning string literal
print(r'\\')
# \\
# print(r'\\\')
# SyntaxError: EOL while scanning string literal

